 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Models Inherit Value Biases from Pretraining
Jan 28, 2026Reward models (RMs) are central to aligning large language models (LLMs) with human values but have received less attention than pre-trained and post-trained LLMs themselves. Because RMs are initialized from LLMs, they inherit representations that shape their behavior, but the nature and extent of this influence remain understudied. In a comprehensive study of 10 leading open-weight RMs using validated psycholinguistic corpora, we show that RMs exhibit significant differences along multiple dimensions of human value as a function of their base model. Using the "Big Two" psychological axes, we show a robust preference of Llama RMs for "agency" and a corresponding robust preference of Gemma RMs for "communion." This phenomenon holds even when the preference data and finetuning process are identical, and we trace it back to the logits of the respective instruction-tuned and pre-trained models. These log-probability differences themselves can be formulated as an implicit RM; we derive usable implicit reward scores and show that they exhibit the very same agency/communion difference. We run experiments training RMs with ablations for preference data source and quantity, which demonstrate that this effect is not only repeatable but surprisingly durable. Despite RMs being designed to represent human preferences, our evidence shows that their outputs are influenced by the pretrained LLMs on which they are based. This work underscores the importance of safety and alignment efforts at the pretraining stage, and makes clear that open-source developers' choice of base model is as much a consideration of values as of performance.
Can AI mediation improve democratic deliberation?
Jan 09, 2026The strength of democracy lies in the free and equal exchange of diverse viewpoints. Living up to this ideal at scale faces inherent tensions: broad participation, meaningful deliberation, and political equality often trade off with one another (Fishkin, 2011). We ask whether and how artificial intelligence (AI) could help navigate this "trilemma" by engaging with a recent example of a large language model (LLM)-based system designed to help people with diverse viewpoints find common ground (Tessler, Bakker, et al., 2024). Here, we explore the implications of the introduction of LLMs into deliberation augmentation tools, examining their potential to enhance participation through scalability, improve political equality via fair mediation, and foster meaningful deliberation by, for example, surfacing trustworthy information. We also point to key challenges that remain. Ultimately, a range of empirical, technical, and theoretical advancements are needed to fully realize the promise of AI-mediated deliberation for enhancing citizen engagement and strengthening democratic deliberation.
Reward Model Interpretability via Optimal and Pessimal Tokens
Jun 08, 2025



Reward modeling has emerged as a crucial component in aligning large language models with human values. Significant attention has focused on using reward models as a means for fine-tuning generative models. However, the reward models themselves -- which directly encode human value judgments by turning prompt-response pairs into scalar rewards -- remain relatively understudied. We present a novel approach to reward model interpretability through exhaustive analysis of their responses across their entire vocabulary space. By examining how different reward models score every possible single-token response to value-laden prompts, we uncover several striking findings: (i) substantial heterogeneity between models trained on similar objectives, (ii) systematic asymmetries in how models encode high- vs low-scoring tokens, (iii) significant sensitivity to prompt framing that mirrors human cognitive biases, and (iv) overvaluation of more frequent tokens. We demonstrate these effects across ten recent open-source reward models of varying parameter counts and architectures. Our results challenge assumptions about the interchangeability of reward models, as well as their suitability as proxies of complex and context-dependent human values. We find that these models can encode concerning biases toward certain identity groups, which may emerge as unintended consequences of harmlessness training -- distortions that risk propagating through the downstream large language models now deployed to millions.
HiBayES: A Hierarchical Bayesian Modeling Framework for AI Evaluation Statistics
May 08, 2025As Large Language Models (LLMs) and other AI systems evolve, robustly estimating their capabilities from inherently stochastic outputs while systematically quantifying uncertainty in these estimates becomes increasingly important. Further, advanced AI evaluations often have a nested hierarchical structure, exhibit high levels of complexity, and come with high costs in testing the most advanced AI systems. To address these challenges, we introduce HiBayES, a generalizable Hierarchical Bayesian modeling framework for AI Evaluation Statistics. HiBayES supports robust inferences in classical question-answer benchmarks and advanced agentic evaluations, particularly in low-data scenarios (e.g., < 20 data points per evaluation). Built on Generalized Linear Models (GLMs), Bayesian data analysis, and formal model comparison, HiBayES provides principled uncertainty quantification and robust parameter estimation. This paper offers a comprehensive introduction to HiBayES, including illustrative examples, comparisons to conventional statistical methods, and practical guidance for implementing multilevel Bayesian GLMs. Additionally, we provide a HiBayES software package [4] (Beta version) for out-of-the-box implementation.
Increasing happiness through conversations with artificial intelligence
Apr 02, 2025Chatbots powered by artificial intelligence (AI) have rapidly become a significant part of everyday life, with over a quarter of American adults using them multiple times per week. While these tools offer potential benefits and risks, a fundamental question remains largely unexplored: How do conversations with AI influence subjective well-being? To investigate this, we conducted a study where participants either engaged in conversations with an AI chatbot (N = 334) or wrote journal entires (N = 193) on the same randomly assigned topics and reported their momentary happiness afterward. We found that happiness after AI chatbot conversations was higher than after journaling, particularly when discussing negative topics such as depression or guilt. Leveraging large language models for sentiment analysis, we found that the AI chatbot mirrored participants' sentiment while maintaining a consistent positivity bias. When discussing negative topics, participants gradually aligned their sentiment with the AI's positivity, leading to an overall increase in happiness. We hypothesized that the history of participants' sentiment prediction errors, the difference between expected and actual emotional tone when responding to the AI chatbot, might explain this happiness effect. Using computational modeling, we find the history of these sentiment prediction errors over the course of a conversation predicts greater post-conversation happiness, demonstrating a central role of emotional expectations during dialogue. Our findings underscore the effect that AI interactions can have on human well-being.
Language Agents as Digital Representatives in Collective Decision-Making
Feb 13, 2025



Consider the process of collective decision-making, in which a group of individuals interactively select a preferred outcome from among a universe of alternatives. In this context, "representation" is the activity of making an individual's preferences present in the process via participation by a proxy agent -- i.e. their "representative". To this end, learned models of human behavior have the potential to fill this role, with practical implications for multi-agent scenario studies and mechanism design. In this work, we investigate the possibility of training \textit{language agents} to behave in the capacity of representatives of human agents, appropriately expressing the preferences of those individuals whom they stand for. First, we formalize the setting of \textit{collective decision-making} -- as the episodic process of interaction between a group of agents and a decision mechanism. On this basis, we then formalize the problem of \textit{digital representation} -- as the simulation of an agent's behavior to yield equivalent outcomes from the mechanism. Finally, we conduct an empirical case study in the setting of \textit{consensus-finding} among diverse humans, and demonstrate the feasibility of fine-tuning large language models to act as digital representatives.
Flexible task abstractions emerge in linear networks with fast and bounded units
Nov 06, 2024
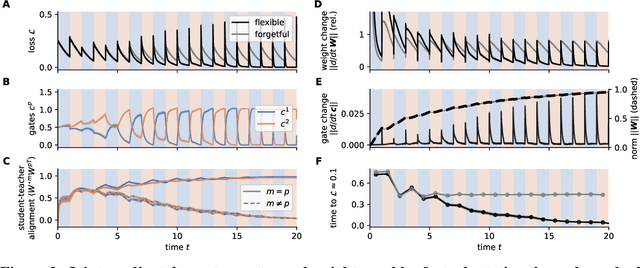

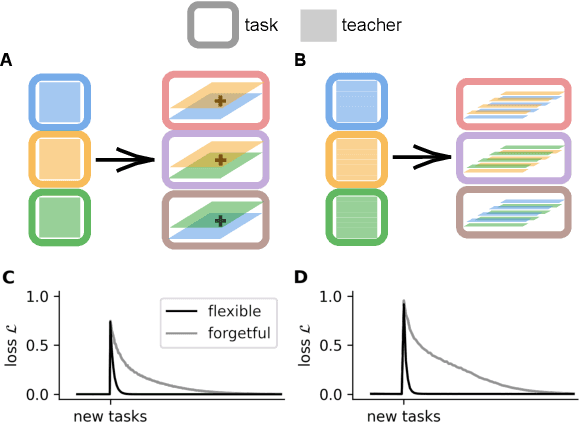
Animals survive in dynamic environments changing at arbitrary timescales, but such data distribution shifts are a challenge to neural networks. To adapt to change, neural systems may change a large number of parameters, which is a slow process involving forgetting past information. In contrast, animals leverage distribution changes to segment their stream of experience into tasks and associate them with internal task abstracts. Animals can then respond flexibly by selecting the appropriate task abstraction. However, how such flexible task abstractions may arise in neural systems remains unknown. Here, we analyze a linear gated network where the weights and gates are jointly optimized via gradient descent, but with neuron-like constraints on the gates including a faster timescale, nonnegativity, and bounded activity. We observe that the weights self-organize into modules specialized for tasks or sub-tasks encountered, while the gates layer forms unique representations that switch the appropriate weight modules (task abstractions). We analytically reduce the learning dynamics to an effective eigenspace, revealing a virtuous cycle: fast adapting gates drive weight specialization by protecting previous knowledge, while weight specialization in turn increases the update rate of the gating layer. Task switching in the gating layer accelerates as a function of curriculum block size and task training, mirroring key findings in cognitive neuroscience. We show that the discovered task abstractions support generalization through both task and subtask composition, and we extend our findings to a non-linear network switching between two tasks. Overall, our work offers a theory of cognitive flexibility in animals as arising from joint gradient descent on synaptic and neural gating in a neural network architecture.
Early learning of the optimal constant solution in neural networks and humans
Jun 25, 2024



Deep neural networks learn increasingly complex functions over the course of training. Here, we show both empirically and theoretically that learning of the target function is preceded by an early phase in which networks learn the optimal constant solution (OCS) - that is, initial model responses mirror the distribution of target labels, while entirely ignoring information provided in the input. Using a hierarchical category learning task, we derive exact solutions for learning dynamics in deep linear networks trained with bias terms. Even when initialized to zero, this simple architectural feature induces substantial changes in early dynamics. We identify hallmarks of this early OCS phase and illustrate how these signatures are observed in deep linear networks and larger, more complex (and nonlinear) convolutional neural networks solving a hierarchical learning task based on MNIST and CIFAR10. We explain these observations by proving that deep linear networks necessarily learn the OCS during early learning. To further probe the generality of our results, we train human learners over the course of three days on the category learning task. We then identify qualitative signatures of this early OCS phase in terms of the dynamics of true negative (correct-rejection) rates. Surprisingly, we find the same early reliance on the OCS in the behaviour of human learners. Finally, we show that learning of the OCS can emerge even in the absence of bias terms and is equivalently driven by generic correlations in the input data. Overall, our work suggests the OCS as a universal learning principle in supervised, error-corrective learning, and the mechanistic reasons for its prevalence.
Using deep reinforcement learning to promote sustainable human behaviour on a common pool resource problem
Apr 23, 2024



A canonical social dilemma arises when finite resources are allocated to a group of people, who can choose to either reciprocate with interest, or keep the proceeds for themselves. What resource allocation mechanisms will encourage levels of reciprocation that sustain the commons? Here, in an iterated multiplayer trust game, we use deep reinforcement learning (RL) to design an allocation mechanism that endogenously promotes sustainable contributions from human participants to a common pool resource. We first trained neural networks to behave like human players, creating a stimulated economy that allowed us to study how different mechanisms influenced the dynamics of receipt and reciprocation. We then used RL to train a social planner to maximise aggregate return to players. The social planner discovered a redistributive policy that led to a large surplus and an inclusive economy, in which players made roughly equal gains. The RL agent increased human surplus over baseline mechanisms based on unrestricted welfare or conditional cooperation, by conditioning its generosity on available resources and temporarily sanctioning defectors by allocating fewer resources to them. Examining the AI policy allowed us to develop an explainable mechanism that performed similarly and was more popular among players. Deep reinforcement learning can be used to discover mechanisms that promote sustainable human behaviour.
Regularised neural networks mimic human insight
Feb 22, 2023



Humans sometimes show sudden improvements in task performance that have been linked to moments of insight. Such insight-related performance improvements appear special because they are preceded by an extended period of impasse, are unusually abrupt, and occur only in some, but not all, learners. Here, we ask whether insight-like behaviour also occurs in artificial neural networks trained with gradient descent algorithms. We compared learning dynamics in humans and regularised neural networks in a perceptual decision task that provided a hidden opportunity which allowed to solve the task more efficiently. We show that humans tend to discover this regularity through insight, rather than gradually. Notably, neural networks with regularised gate modulation closely mimicked behavioural characteristics of human insights, exhibiting delay of insight, suddenness and selective occurrence. Analyses of network learning dynamics revealed that insight-like behaviour crucially depended on noise added to gradient updates, and was preceded by ``silent knowledge'' that is initially suppressed by regularised (attentional) gating. This suggests that insights can arise naturally from gradual learning, where they reflect the combined influences of noise, attentional gating and regularisation.